
Нейросети в медицине, гуманитарной науке и кибербезопасности — в девятом выпуске рассказываем о проектах, которые делают технологии ближе и полезнее.
- В Москве ИИ-агент обработал более 2 млн медкарт и ускорил работу врачей
- Positive Technologies запустила крупнейший в России портал об уязвимостях
- В Москве открылся Qubot — первый в России шоурум-магазин робототехники и ИИ
- Студента НГУ разработала ИИ-приложение для оцифровки классических тибетских текстов
- T-Банк выпустил T-Pro 2.0 — открытую LLM с гибридной логикой и экономией ресурсов
В Москве ИИ-агент обработал более 2 млн медкарт и ускорил работу врачей
Анастасия Ракова, заместитель мэра Москвы по вопросам социального развития, рассказала о результатах применения ИИ-технологий в московской системе здравоохранения. Всего за месяц сервис для автоматического создания сводок из электронной медкарты (ЭМК) пациента перед приёмом создал более 2 миллионов саммари, и ежедневно этот показатель увеличивается примерно на 44 тысячи.

В электронной медкарте сегодня аккумулировано свыше 4,2 миллиарда записей, при этом ЭМК одного пациента может включать десятки протоколов осмотров, данные результатов анализов, вызовов скорой помощи и назначений. Мы запустили в столице ИИ-агента для саммаризации сведений из электронных медицинских карт москвичей. Благодаря этому врач может быстрее принять решение, а пациент — получить помощь без задержек.
Анастасия Ракова, заместитель мэра Москвы по вопросам социального развития
ИИ-агент анализирует историю обращений, результаты обследований, назначения, протоколы осмотров, данные скорой помощи и другие сведения, помогая врачу быстро сориентироваться по каждому визиту пациента.
Задачи искусственного интеллекта:
- Саммаризация медкарты — ИИ подготавливает краткую сводку из ЭМК на основе жалоб и истории болезни.
- Интеллектуальный опросник — до визита уточняет жалобы и собирает первичную информацию.
- Сервис «ТОП-3» — предлагает врачу три возможных предварительных диагноза и формирует список исследований.
- Сервис «ТОП-1» — помогает определить итоговый диагноз на основе всех клинических данных.
- Все сервисы интегрированы в единую цифровую платформу ЕМИАС и работают в комплексе.
В разработке системы также принимали участие «СберМедИИ» и «Лаборатория ИИ Сбера». Авторы проекта подчеркивают, что ИИ выполняет только вспомогательную функцию: заключительное клиническое решение всегда принимает врач.
Почему это важно:
- Сервис уменьшает нагрузку на врачей и ускоряет принятие решений.
- Повышает точность диагностики за счёт структурированного анализа данных.
- Улучшает персонализацию помощи для пациентов.
- Демонстрирует зрелость цифровой медицины в мегаполисе.
- Интеграция ИИ-агентов в реальную практику — шаг к медицине будущего.
Positive Technologies запустила крупнейший в России портал об уязвимостях
Компания Positive Technologies запустила общедоступный портал, где аккумулируются сведения об уязвимостях в программном обеспечении и оборудовании от производителей со всего мира. Сейчас на платформе представлено свыше 317 000 уязвимостей, включая информацию об их критичности, статусе устранения и авторах исследований. Еженедельно база пополняется тысячей новых записей.
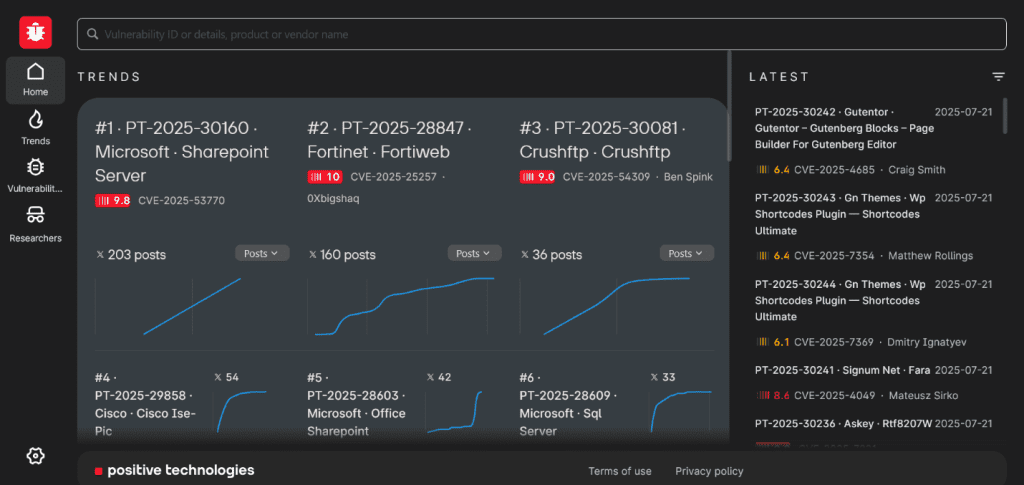
Портал предназначен для этичных хакеров, специалистов по ИБ и корпоративных команд, которым важно получать полную и своевременную информацию о безопасности продуктов. Запуск стал ответом на снижение активности глобальных баз, таких как CVE/NVD.
Более чем за 20 лет работы мы накопили обширную базу знаний об уязвимостях в продуктах зарубежных и отечественных поставщиков. Переработав и обогатив ее, мы создали интерактивный портал, который, надеемся, будет полезен и независимым исследователям, и службам ИБ. Мы поставили своей целью сделать его надежным и достаточным источником информации обо всех выявляемых в мире ИБ уязвимостях.
Дмитрий Серебрянников, директор по анализу защищенности в Positive Technologies
Как работает портал:
- Информация агрегируется из CVE, NVD, Telegram, Reddit, X.com и других источников.
- LLM-модель подготавливает сводные описания уязвимостей — более точные и развернутые.
- Учитываются фактические авторы обнаружения, что редко делают другие базы.
- Отмечаются наиболее обсуждаемые уязвимости — формируется рейтинг актуальных угроз.
- В планах: персональные ленты, подписки на исследователей и собственные профили, как в bug bounty-сервисах.
Почему это важно:
- Независимость от зарубежных источников: портал восполняет пробелы в глобальных базах данных.
- Система фиксирует авторство уязвимостей, включая тех, кого не упоминают международные реестры.
- Использование ИИ позволяет структурировать данные и представить их в удобной форме.
- Создание живого профессионального сообщества.
- Доступ к оперативной информации помогает быстрее реагировать на угрозы, снижая риски для бизнеса и критической инфраструктуры.
В Москве открылся Qubot — первый в России шоурум-магазин робототехники и ИИ
В центре Москвы начал работу Qubot — первый в стране интерактивный шоурум-магазин, в котором собраны самые яркие представители современной робототехники. В магазине представлены устройства разных форматов: от гуманоидов и робособак до GPT-компаньонов и экзоскелетов. Qubot стал пространством для знакомства с технологиями будущего — все устройства доступны для тестирования и живого общения.

Что можно увидеть в Qubot
Гуманоидные роботы:
- Unitree G1 — робот с ИИ и системой стабилизации, имитирует движения человека, используется в исследованиях и обучении.
- Robosen K1 — программируемый обучающий робот для подростков и начинающих разработчиков.

Роботы-собаки:
- Unitree Go2 Air — с лидаром и голосовым управлением, безопасен в публичных местах.
- Loona Pet Bot — помощник по уходу за домашними животными.

Роботы-компаньоны:
- Weilan Babyalpha A2 — ИИ-питомец с GPT, распознаёт эмоции и ведёт диалоги.
- Eilik и Emo — мини-компаньоны, запоминают привычки, реагируют на прикосновения.
- Robert — детский робот, танцует, играет, реагирует на голос.
Сервисный робот:
- Pudu KettyBot Pro — обслуживает в кафе и отелях, доставляет заказы, показывает рекламу
Экзоскелет:
- Hypershell Pro X — снижает нагрузку при ходьбе и переноске веса, до 25 км без подзарядки
Посетить шоурум-магазин можно в Москве по адресу улица Арбат, 13.
Почему это важно:
- Первый в России физический шоурум, объединяющий ИИ и робототехнику в формате «попробуй сам».
- Доступ к актуальным потребительским и профессиональным решениям — от развлечений до индустриального применения.
- Популяризация технологий среди широкой аудитории.
- Возможность протестировать устройства перед покупкой и оценить их реальные возможности.
- Шаг к формированию пользовательской культуры общения с ИИ и роботами в повседневной жизни.
Студента НГУ разработала ИИ-приложение для оцифровки классических тибетских текстов
Анна Мурашкина, студентка направления «Фундаментальная и прикладная лингвистика» НГУ и сотрудница ИВМиМГ СО РАН, создала приложение на базе машинного обучения для распознавания, транслитерации и анализа классических тибетских текстов. Разработка умеет работать со старопечатными рукописями и ксилографами XVIII–XX веков, выполненными тибетским слоговым письмом.

Приложение уже демонстрирует лучшую точность, чем существующие открытые решения, такие как Tesseract.
Для этого я вручную выполнила лингвистическую разметку строк тибетского текста из фонда ИМБТ СО РАН. Затем с учетом специфики тибетской графики разработала систему оценки качества оптического распознавания символов (OCR). Далее я провела сравнение существующих архитектур и выбрала модель сверточной нейросети, которая потребовала дообучения.
Анна Мурашкина, студентка направления «Фундаментальная и прикладная лингвистика» НГУ
В основу разработки легли материалы Центра восточных рукописей и ксилографов ИМБТ СО РАН, где хранятся около 70 тысяч хроник, многие из которых рискуют быть утраченными из-за физического старения. Старопечатные документы, рукописи и ксилографы содержат уникальные сведения о философии, религии, медицине, истории и искусстве.
Как работает система:
- Модель автоматически распознаёт тибетские символы с изображений, превращая их в машиночитаемый текст.
- Включает модули предобработки, сегментации, распознавания и постобработки.
- Лингвистическая разметка выполнена вручную с учётом особенностей тибетской графики.
- Создана система оценки качества OCR специально для нестандартных исторических документов.
- Результат — полноценный инструмент для оцифровки тибетских текстов с высоким уровнем точности.
Уникальная программная платформа, предназначенная для автоматизированной обработки документов на тибетском языке, будет востребована исследователями, архивными работниками и библиотекарями. Новый фреймворк должен способствовать сохранению тибетского текстового наследия, являющегося в том числе частью культурного достояния бурятского народа.
Пресс-служба НГУ
Почему это важно:
- Система вносит вклад в сохранение уникального культурного наследия.
- Расширяет возможности цифровой гуманитаристики и автоматизированной лингвистики.
- Применимо в академических архивах по всему миру.
- Повышает точность OCR для сложных письменностей, не охваченных коммерческими решениями.
- Развивает научное сотрудничество между российскими и международными институтами в сфере цифровизации исторических текстов.
T-Банк выпустил T-Pro 2.0 — открытую LLM с гибридной логикой и экономией ресурсов
Группа «Т-Технологии» (входит в экосистему Т-Банка) выпустила большую языковую модель с гибридным режимом рассуждений — T-Pro 2.0. Модель входит в семейство Gen-T и уже демонстрирует высокую эффективность в русскоязычных задачах.
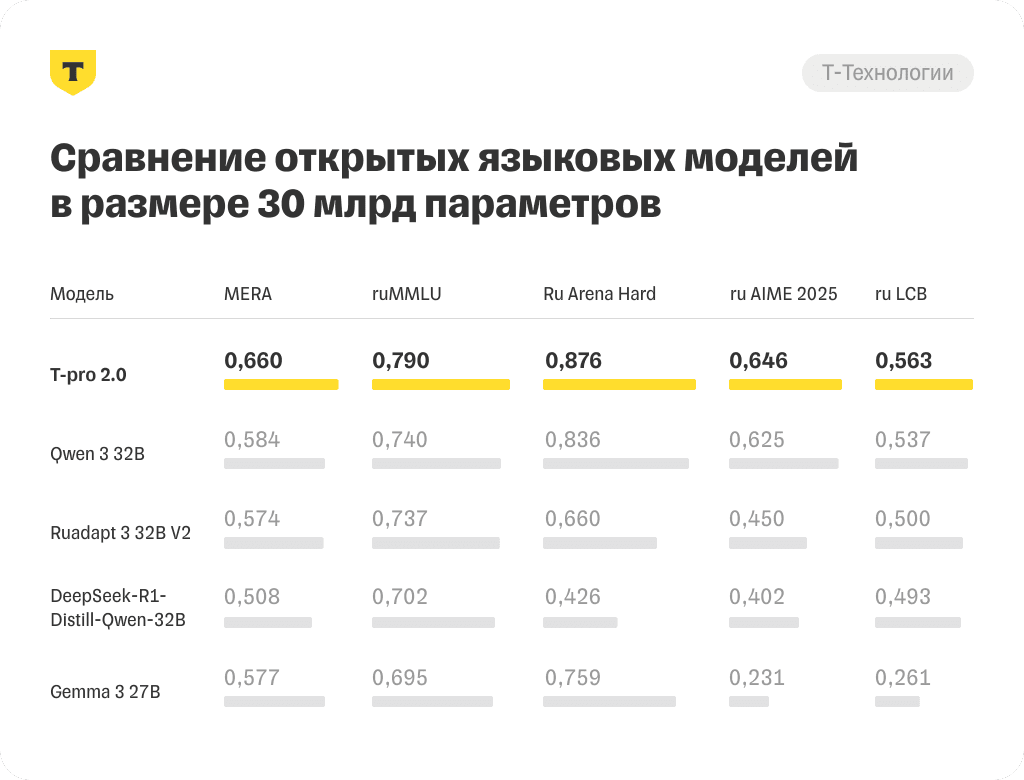
T-Pro 2.0 сочетает в себе два режима работы: быстрые ответы на простые запросы и глубокий анализ — на сложные. Такой подход позволяет сократить вычислительные затраты более чем вдвое по сравнению с Qwen 3 и DeepSeek R1-Distil, не жертвуя качеством.
T-Pro 2.0 сочетает лучшее качество среди открытых моделей в размере 30 миллиардов параметров с практичностью при внедрении — более быстрая генерация рассуждений на любом кириллическом языке дает в среднем двукратную экономию вычислительных ресурсов по сравнению с доступными аналогами.
Виктор Тарнавский, директор по искусственному интеллекту Т-Банка
Ключевые возможности T-Pro 2.0:
- Число параметров — 32 млрд.
- Обрабатывает сложные аналитические запросы и генерирует точные ответы на русском языке
- Поддерживает гибридный режим рассуждений — экономит ресурсы при массовом внедрении
- Лидер по результатам русскоязычных бенчмарков: MERA, ruMMLU, Ru Arena Hard, ruAIME, ruLCB.
- Используется в ИИ-ассистентах и копайлотах Т-Банка: 40% обращений обрабатываются без участия человека
- Основана на внутренних данных Т-Банка, что повысило автономность агентов на 10%
Модель T-Pro 2.0 доступна под открытой лицензией Apache 2.0 на Hugging Face.
Почему это важно:
- Существенно снижает стоимость внедрения ИИ в бизнес-процессы.
- Демонстрирует конкурентоспособность отечественных моделей в русскоязычной среде
- Поддерживает открытость и развитие сообщества — распространяется по свободной лицензии.
- Обеспечивает более высокую автономность ИИ-агентов, работающих напрямую с пользователями.
- Создаёт основу для построения ИИ-решений нового поколения — от поддержки до операционного управления.
Подписывайся на наш Telegram-канал — там мы рассказываем о главных достижениях России в IT, науке, космосе и инженерии. Если у тебя есть интересные новости о российских технологиях, присылай их на support@codenrock.com.







