Коротко
- X5 Tech провела ML-хакатон X5 Tech AI Hack на Codenrock с призовым фондом 2 000 000 рублей: 722 заявки, 75 команд от junior до senior.
- Трек 1 — NER-алгоритм маскирования чувствительных данных (ФИО, e-mail, телефоны, url) с заменой на синтетические значения, метрика F1 Macro.
- Трек 2 — детекция галлюцинаций LLM: бинарная классификация ответов «корректный/с галлюцинациями» по метрике F1 Micro.
- За соревнование отправлено 686 решений, 455 собрались успешно; в пике задействовалось до 15 CPU-серверов.
- ИИ-помощник Codenrock 175 раз анализировал логи сборок и в 153 случаях дал корректные рекомендации по исправлению ошибок.
Обновлено: 23 июля 2025

X5 Tech провела соревнование для ML-разработчиков X5 Tech AI Hack с призовым фондом в 2 000 000 рублей на платформе Codenrock. Хакатон прошел в преддверии Х5 Future Night – антиконференции, на которой лучшие профессионалы из различных отраслей российского рынка вместе оценивали настоящее и заглядывали в будущее ритейла.
Участники хакатона решали продуктовые задачи на базе реальных бизнес-кейсов в двух треках: разрабатывали алгоритм маскирования чувствительных данных в датасете и избавляли генеративные нейросети от галлюцинаций. На конференции состоялась церемония награждения победителей.
Подробнее о мероприятии – в этом кейсе.
Начало хакатона
Участники X5 Tech AI Hack оставляли заявки на платформе Codenrock, предварительно заполнив анкету с данными о себе. Свое желание поучаствовать в хакатоне высказали 722 человека, которые сформировали 75 команд. Основные навыки участников: Python, C++, SQL, Git, Data Science, квалификация – от junior до senior.
На соревновании у конкурсантов была возможность продемонстрировать:
- навыки работы в области машинного обучения и искусственного интеллекта;
- умения в области NLP (Natural Language Processing), в частности, в задачах NER (Named Entity Recognition) и классификации текстов;
- навыки работы с данными, их обработки и анализа;
- знания о Python, TensorFlow и Keras, популярных библиотеках для разработки и обучения моделей машинного обучения, включая глубокое обучение.

Основной этап X5 Tech AI Hack стартовал 17 мая. Участники первого трека решали задачу по маскированию данных.
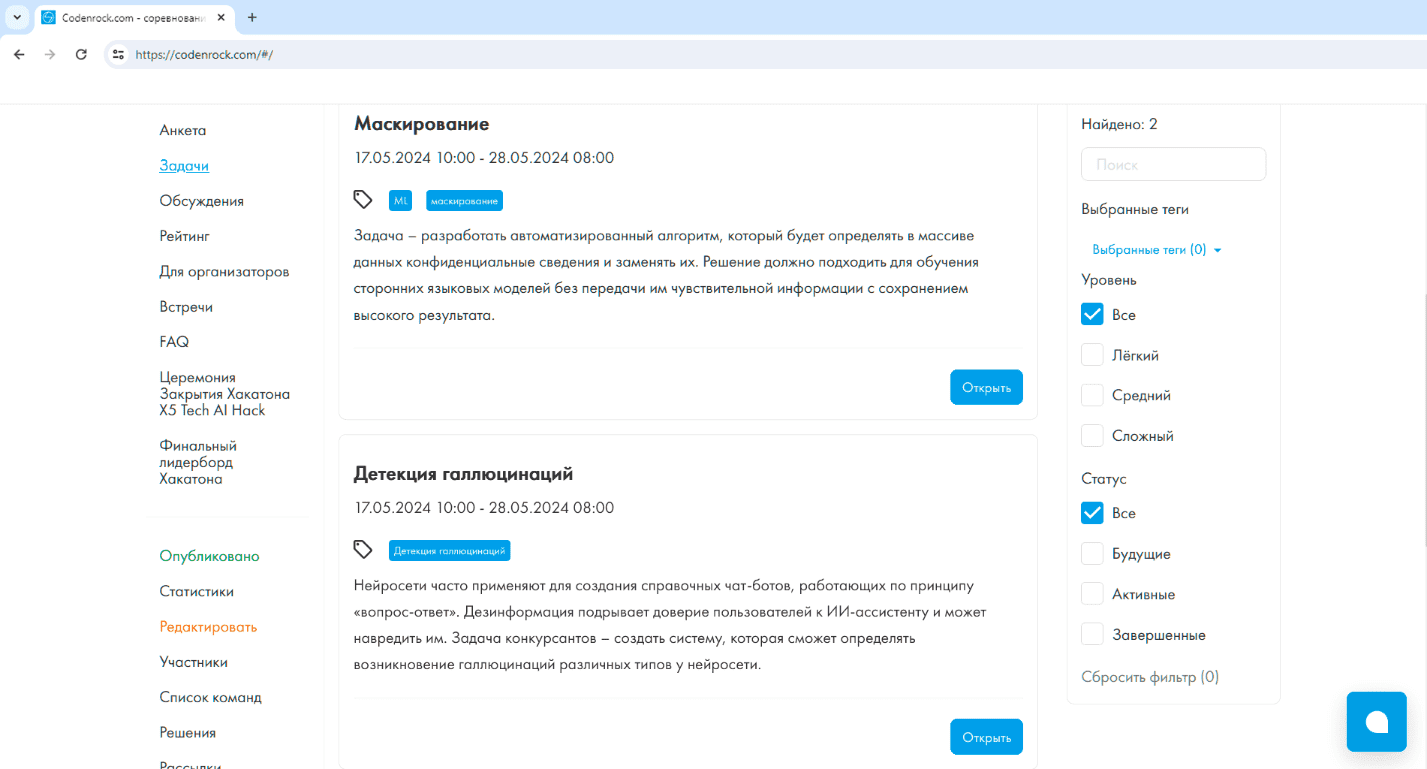
Трек 1. Маскирование данных
Решаемая проблема. Современный IT ландшафт требует от крупных компаний гибкого подхода при работе с чувствительными данными. Например, их замена необходима, если эти сведения используются в сторонних LLM (Large Language Models). Передача важной информации вовне недопустима, поэтому нужен сервис, который способен автоматически маскировать данные. Такой подход позволит сохранить чувствительные сведения в контуре компании и одновременно не исказить качество получаемых результатов.
Задача участников. Командам предстояло решить классическую для NLP задачу NER по выделению и классификации именованных сущностей в тексте. Для кейса X5 было необходимо определить в предоставленных данных чувствительные сведения и их категорию: фамилия, имя, отчество, электронная почта, телефонный номер, адрес, имя хоста, url.
Датасет был представлен набором текстов, в которых присутствовали эти сущности в разных форматах (с указанием части текста, относящейся к той или иной категории для обучающего множества). В тестовое множество были включены тексты, для которых требовалось определить заданные категории сведений.
На основе этих данных участникам предстояло разработать алгоритм замены чувствительной информации на схожие синтетические значения (например, фамилию «Петров» заменить на «Сидоров», url x5.ru на m8.ru и т.д.). Решение должно исключать обратное демаскирование извне.
Итоговый результат – готовое решение, которое достигнет высокой точности по метрике F1 Macro. Расчет велся по нескольким лейблам:
entity_group_types = {'ORG', 'NUM', 'NAME_EMPLOYEE', 'LINK', 'DATE', 'ACRONYM', 'MAIL', 'TELEPHONE', 'TECH', 'NAME', 'PERCENT}Пока участники первого трека хакатона решали задачу по маскированию данных, командам, выбравшим второй кейс, предстояло разработать алгоритм определения галлюцинаций у нейросетей.
Трек 2. Детекция галлюцинаций
Решаемая проблема. Большие языковые модели часто используются для создания вопросно-ответных систем. Пользователь ожидает от них корректной информации. К сожалению, современные LLM подвержены «галлюцинациям» при решении данной задачи – аномалиям генерации, которые кажутся бессмысленными или не соответствующим представленным входным данным.
Поэтому необходим алгоритм, который сможет определять неправильные ответы, чтобы снизить риски применения языковых моделей в реальных задачах и увеличить доверие пользователей к технологии.
Задача участников. В рамках кейса командам предстояло классифицировать текст как «корректный» или «с галлюцинациями». Желательно, чтобы этот подход мог применяться к различным типам аномалий генерации, потому что в обучающих и тестовых данных были представлены разные варианты артефактов.
Обучающее множество представляло собой набор [текст документа] — [контекст] — [бинарная метка]. Для тестового множества требовалось по тексту документа и контексту определить метку.
Итоговый результат – готовое решение, которое достигнет высокой точности по метрике F1 Micro. Расчет проводился по двум лейблам: да/нет.
Для задач было достаточно использовать CPU-only сервера, количество которых горизонтально масштабировалось в зависимости от активности участников. В самые жаркие часы их кол-во достигало 15 штук.
Никита Хорев, технический директор Codenrock
Основной этап соревнования
Для работы над задачами участники получили доступ к базовому репозиторию в Gitlab. После каждой команды git push проект автоматически собирался из ветки main согласно Dockerfile в корне. Логи сборки участники могли просмотреть в разделе CI/CD «Jobs».
На Codenrock интегрирован ИИ помощник, который анализирует логи сборки и инференсов решений участников. Он вычленяет из всех логов ошибки и дает рекомендации, как их исправить.
За всё время соревнования участники отправили на проверку 686 решений.Разбивка по статусам:
выполнились успешно: 455
закончились ошибкой: 209
другое (были отменены): 22
Участники 175 раз воспользовались помощью ИИ помощника Codenrock для анализа логов своих решений.
ИИ дал корректный ответ: 153
ИИ не справился с ответом: 22Мы отметили высокую эффективность ИИ помощника в сравнении с ручной выгрузкой и анализом логов, как это было раньше.
Никита Хорев, технический директор Codenrock

В случае успешной сборки команда могла запустить проверку решения и расчет модели с помощью соответствующей кнопки. После завершения этой задачи на e-mail приходило уведомление о результатах.
Мы предоставили интегрированную в платформу систему для хранения кода (git), в рамках которой участники работали над задачами. Предоставили базовые решения по обеим задачам, которые позволили понизить уровень входа в задачу, сделать её понятней, ознакомиться с проверочной системой.
Организовали автоматизированную проверку решений участников путем контейнеризации их решений, запуска программ и получения предсказаний, а также автоматическую оценку точности предсказаний (скоринг).
Никита Хорев, технический директор Codenrock
Отслеживать эффективность своего решения в сравнении с проектами соперников участники могли на публичном лидерборде, в котором отображались итоги последних проверок моделей. В таблице можно было наглядно увидеть, как изменения помогают догнать конкурентов или, напротив, понижают позицию в рейтинге по целевой метрике.
11 команд, разработавших лучшие решения, получили приглашение на конференцию Х5 Future Night, где прошли финальные питчинги и церемония награждения.
Финал соревнования

X5 Future Night – площадка для обсуждения технологий и бизнеса в формате антиконференции, которая собрала экспертов и профессионалов различных отраслей российского рынка. Количество офлайн и онлайн участников мероприятия – несколько тысяч человек.
Одним из ярких событий X5 Future Night стал финал хакатона X5 Tech AI Hack. Авторы 11 лучших решений приехали на конференцию, чтобы защитить свои проекты перед жюри и побороться за призовой фонд в 2 000 000 рублей. У каждой команды было 5 минут на презентацию решения и еще 5 – на ответы на вопросы экспертов соревнования.

При оценке проектов эксперты учитывали:
- Качество кода: успешность прохождения кода через линтеры и форматтеры, быстрый процесс настройки и первого запуска, отсутствие лишних зависимостей, наличие документации и комментариев.
- Ресурсоемкость и скорость работы: низкий уровень потребления CPU, RAM и YRAM для работы решения и высокая скорость инференса
- Масштабируемость: возможность превращения проекта в рабочий сервис и добавления новых инстансов предполагаемого сервиса, простота расширения на новые классы и данные.
По итогам выступлении жюри определили трех победителей в каждом треке.
Победители хакатона
Трек 1. Маскирование. Лучшие решения представили:
🥇 Команда shaitan machine – 1 место, 500 000 рублей. Участники разработали сервис, на базе которого можно запустить готовый продукт.
🥈 Команда «Лидируй катбустируй» – 2 место, 300 000 рублей. Были очень хорошо исследованы данные – команда смогла составить списки с сущностями, которые необходимо замаскировать.
🥉 Команда E-LAN – 3 место, 200 000 рублей. Одни из немногих, кто практически не использовал регулярные выражения в коде, также подготовили хорошую документацию и качественный код, который позволяет развернуть сервис.
Трек 2. Детекция галлюцинаций. Жюри высоко оценило проекты этих участников:
🥇 Команда Wer – 1 место, 500 000 рублей. Участники представили подробную документацию, в которой описано, что делали и пробовали в процессе, дообучили модель на расширенных данных и написали отличный код, упрощающий запуск готового сервиса.
🥈 Команда madgnome – 2 место, 300 000 рублей. Собрали данные и дообучили модель на расширенном датасете, добавили модель второго уровня для повышения точности предсказаний. Жюри отметило высокое качество кода, из которого было понятно, как собрать работающий сервис.
🥉 Команда DeepPavlov Lab – 3 место, 200 000 рублей. Подготовили отличную документацию с понятным описанием, разработали практически готовый сервис с моделью второго уровня для улучшения качества предсказаний.

Все команды из ТОП-10 получили промокод на годовую подписку X5 Пакет для кэшбека в магазинах, а финалисты – мерч компании.
Отзывы организаторов
Департамент по анализу данных Х5 Tech занимается широким набором вопросов: начиная от решения классических задач ритейла, заканчивая RnD-направлением и проведением экспериментов и тестов. Мы много взаимодействуем с сообществом: поддерживаем большую лабораторию искусственного интеллекта в ИТМО, активно сотрудничаем с ВШЭ и МФТИ.
В рамках хакатона хотели обратиться за новым взглядом на те проблемы, которые решаем. Мы сейчас находимся в непонятной точке преломления, когда ИИ-технологии уже очень сильно выросли, но большого количества промышленных эксплуатаций, хороших, правильных, полезных, еще не видим. Для этого и провели этот хакатон. Спасибо всем, кто принял участие.
Михаил Неверов, директор по анализу данных Х5 Tech



Частые вопросы
Что такое X5 Tech AI Hack и какой был призовой фонд?
Соревнование X5 Tech для ML-разработчиков на платформе Codenrock с призовым фондом 2 000 000 рублей, прошедшее в преддверии антиконференции Х5 Future Night. Заявки подали 722 человека, сформировавшие 75 команд с навыками Python, C++, SQL, Git и Data Science — от junior до senior.
Какие задачи решали участники X5 Tech AI Hack?
Два трека: маскирование чувствительных данных — NER-задача по выделению ФИО, e-mail, телефонов, адресов и URL с заменой на синтетические значения (метрика F1 Macro), и детекция галлюцинаций — бинарная классификация ответов LLM как корректных или с галлюцинациями (метрика F1 Micro).
Как была организована проверка решений на хакатоне?
Команды работали в базовом репозитории GitLab: после каждого git push проект автоматически собирался из ветки main по Dockerfile, логи были видны в CI/CD «Jobs». Всего отправлено 686 решений: 455 успешных, 209 с ошибкой, 22 отменены. Для расчётов хватило CPU-серверов, масштабируемых до 15 штук в пиковые часы.
Как ИИ-помощник Codenrock помогал участникам?
Интегрированный в платформу ИИ анализировал логи сборки и инференсов, вычленял ошибки и давал рекомендации по исправлению. Участники обратились к нему 175 раз: в 153 случаях ИИ дал корректный ответ, в 22 — не справился. Организаторы отметили его высокую эффективность по сравнению с ручным анализом логов.







